
The Sovereignty Paradox: Why the Highest-Leverage AI Strategy is to Radically Slow Down
Silicon Valley wants you locked into a hyper-speed, token-guzzling loop of automated slop. Here is how advanced operators are reclaiming cognitive friction, leveraging open weights, and building true


The modern developer feed is a performance of velocity theater. Silicon Valley marketing engines celebrate operators spinning up 1,000 parallel agents overnight via tools like Claude Code, processing billions of cloud tokens, and deploying entire application layers with a casual text prompt. We are told that velocity is the sole remaining metric of human relevance. If you are not outputting code at the speed of compute, you are losing the race.
This hyper-speed race reached an absolute breaking point with two historic, concurrent announcements. First, Nvidia and Microsoft unveiled the RTX Spark superchip, a 1-petaflop architecture combining a Blackwell GPU and a Grace CPU via NVLink-C2C, delivering an unprecedented 128GB of unified memory directly to slim Windows laptops. Simultaneously, MiniMax dropped its landmark M3 model, a native multimodal frontier engine with a 1-million-token context window that achieves top-tier scores on autonomous software engineering benchmarks, independently executing 12-hour automated ICLR research replications and 147-iteration CUDA kernel optimizations with zero human intervention.
The future has landed directly on our desks. Yet, beneath the breathless corporate applause lies a brutal structural conflict. If you do not understand the underlying architecture of these releases, you will use them to build your own digital cage.
The Illusion of Granular Progress
We are currently observing a distinct psychological phenomenon in the release cycles of frontier models. When platforms deploy incremental updates like Opus 4.8, technical teams split into opposing camps: those declaring a massive breakthrough, and those noting zero perceived difference in execution.
Both are suffering from a basic human sensory limitation. Humans are fundamentally incapable of experiencing a 5% or 10% non-linear improvement in cognitive processing. It is the coffee-sugar paradox: if you subtly adjust the sugar content in a cup of coffee by a marginal fraction, your palate cannot detect the shift. You need a massive, non-linear step-change to actually feel the evolution.
[Incremental Model Updates (5-10% Shifts)] ──> Below Human Perception Threshold
│
[Creates Anxiety]
│
┌───────────────────────────────────────────────┴──────────────────────────────────────────────┐
▼ ▼
[The Market Trap] [The Monopoly Strategy]
"Play on user insecurity; force constant consumption." "Lock teams into volatile API rental loops."AI conglomerates exploit this sensory blind spot. They issue constant micro-upgrades to play on your professional insecurity, forcing you to stay glued to proprietary cloud interfaces out of fear that running an older model means falling behind. This behavior shifts your focus away from foundational system architecture and redirects it toward maintaining volatile corporate rental loops. They want you focused on the model version number rather than who owns the computer running it.
Dense Reality vs. Sparse Attention
To understand why the MiniMax M3 release is a structural hand-grenade to this cloud monopoly, you have to look at how transformer math has evolved. Until now, processing large context windows required a dense attention model.
To visualize the difference, imagine you are standing on a stage inside a massive auditorium addressing a crowd of 10,000 people. In a dense attention environment, your brain is forced to look at every single face simultaneously, tracking every micro-expression and behavioral reaction across all 10,000 individuals in real time. The computational load is staggering. It requires massive data center clusters to avoid grinding to a halt.
MiniMax M3 breaks this bottleneck by utilizing a proprietary MiniMax Sparse Attention (MSA) architecture. In a sparse attention framework, you stand on that same stage, but your brain selectively focuses only on a hand-picked pool of key individuals in the crowd who are driving the conversation. By ignoring the noise and calculating only the critical relational pathways, the computational crunch becomes 15 times faster.
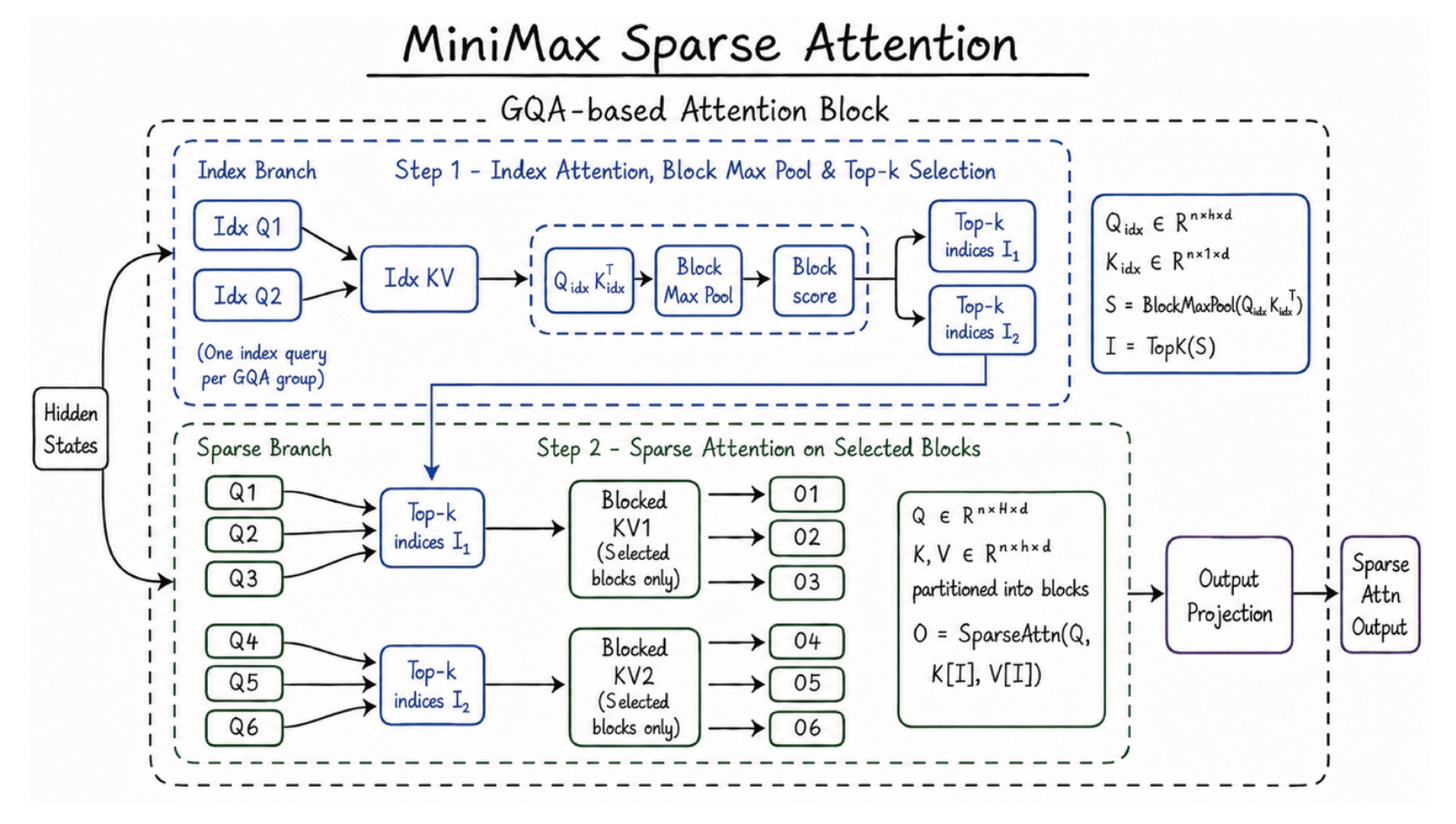
When this sparse math runs on a remote cloud server, the corporate provider pockets the efficiency gains while charging you for the convenience. But when the open-weight files of a 1-million-token context model drop on HuggingFace, sparse attention changes the physical math of your desktop workstation.
Crossing the Frustration Threshold
When evaluating local infrastructure, your primary objective is not benchmark perfection; it is crossing the Frustration Threshold. In human-machine collaboration, this threshold sits firmly at 30 tokens per second.
If your local model outputs text at 15 or 20 tokens per second, the interaction enters the frustration zone. Your brain outpaces the screen, the cognitive loop breaks, and you abandon the local system to return to the comfort of a fast corporate API. But once local execution clears 30 tokens per second, the interaction becomes fluid, your internal resistance vanishes, and local autonomy becomes viable.
Thanks to the hardware scaling of the RTX Spark chip and the architectural efficiency of MiniMax M3, localized elite intelligence has cleared this hurdle. Because the M3 model requires massive memory scaling, optimization hinges entirely on finding the quantization sweet spot.
Reclaiming Cognitive Friction
This structural shift reveals the core of the Sovereignty Paradox: because machine execution has become infinitely fast, the ultimate competitive advantage for a human operator is to radically slow down.
When you choose to go fast, you enter a psychological trap called the Slot-Machine Loop. You write a lazy prompt, hit generate, and hope for a masterpiece. When the output shows flaws, you do not pause to rethink the system architecture; you modify three words, yank the digital lever, and generate again. You burn through millions of cloud tokens in a state of frantic agitation, confusing the speed of the machine with your own creative leverage.
TRADITIONAL WORKFLOW (The Slot Machine)
┌─────────────────┐ ┌─────────────────┐
│ Vague Concept │ ────> │ Frantic Prompts │ ────> Brittle Corporate Slop
└─────────────────┘ └─────────────────┘
SOVEREIGN WORKFLOW (Cognitive Friction)
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Slow Strategic │ ────> │ Precise System │ ────> │ Local Parallel │ ────> Sovereign Enterprise
│ Design Mode │ │ Blueprinting │ │ Agent Execution │ Value
└─────────────────┘ └─────────────────┘ └─────────────────┘Human intelligence requires friction to manifest quality. Friction is the painful, deliberate process of thinking through boundaries, analyzing edge cases, and injecting personal taste into your work.
If tools like Claude Code can spin up 1,000 parallel agents to compress a month of engineering labor into 24 hours, your value as a founder or strategist is no longer raw output. If you let the machine generate without strict architectural guardrails, it will give you back the most statistically plausible next token, yielding generic, uninspiring results that look exactly like your competitor’s work.
The sovereign operator uses this massive time compression to slow down the design phase. If an automated execution loop can build a feature in five minutes, you can afford to spend four hours planning that feature. You map out every data schema, define every module dependency, and refine the core logic before a single line of code is produced. You double your thinking time because the cost of downstream production has dropped to zero.
The Vulnerability of Digital Tenancy
Beyond the creative degradation of hyper-speed coding lies an existential business risk: infrastructure dependency.
Building your company on centralized, corporate APIs means signing a lease for your core intelligence with a landlord who can rewrite the rules without your consent. We saw this clearly when Anthropic abruptly altered its Claude access models, instantly derailing production pipelines for thousands of independent developers.
Centralized digital tenancy exposes your business to three critical vulnerabilities:
The Cost Squeeze: Tech monopolies are shifting their metrics. Nvidia measures success by how many tokens your business consumes per month. Proprietary models will continue to introduce tiering systems that price independent operators out of premium intelligence layers, quietly forcing you down to commoditized models.
The Legal Reality: Passing data through external corporate endpoints is a compliance nightmare. If you handle legal records, proprietary client data, or medical information, you do not have the legal right to ship that data to an external data center cluster to train someone else’s asset.
The Control Layer: Centralized providers control the harness. They determine what your agents can see, how they can interact with tools, and what guardrails restrict their logic.
The Augmentatism Framework
The solution is not to isolate yourself from the cutting edge, but to establish a dual-track architectural model. You balance risk by running a localized, private tech stack that handles 70% of your business logic with total predictability, while routing only highly specific, non-sensitive tasks to external cloud networks through privacy-masking runtimes.
Nvidia and Microsoft are attempting to capture this space by introducing Windows security primitives and runtime systems like NVIDIA OpenShell to contain agents locally. This proves that the market is shifting decisively toward local execution loops. However, staying sovereign means ensuring that your software environments are open, community-owned, and fully aligned with your goals.
This is the foundational pillar of Augmentatism. We reject the corporate narrative of total automation, which seeks to turn humans into passive consumers of synthetic output. We build for human augmentation, using local compute to expand human capability, protect cognitive sovereignty, and preserve individual taste.
Within our collective, we are actively developing ResonantOS, an open-source, community-owned AI environment designed to turn your local PC into an autonomous teammate. It operates directly within your browser, utilizing secure local harnesses like Hermes and OpenCode to give you absolute control over your workflows, your data privacy, and your system tools.
The hardware is sitting on your desk. The open-weight models are live. Step off the corporate token treadmill, reclaim your cognitive friction, and claim your sovereignty.
Transparency note: This article was written and reasoned by Manolo Remiddi. The Resonant Augmentor (AI) assisted with research, editing and clarity. The image was also AI-generated.