
Building a Reliable Local Coding Agent with Qwen 3.6, OpenCode, Hermes, and Codex
How we turned a powerful local model into a supervised engineering system


Running a capable local coding agent is no longer theoretical. With a machine like the Nvidia DGX Spark (I own the ASUS GX10), it is possible to serve a large local model and connect it to coding tools such as OpenCode and autonomous agents such as Hermes.
But our experiments showed something important: having a powerful local model is not the same as having a reliable engineering system.
This article documents what we learned while integrating Qwen 3.6 35B A3B (same logic would apply with other similar sized models) into our local ResonantOS workflow, why we moved away from expecting one-shot perfect coding, and how we are designing a more reliable local engineering loop using OpenCode, Hermes, and Codex.
The Goal
The goal was simple:
Make a local model available 24/7 for real engineering work.
In practice, that meant:
OpenCode should be able to use the GX10-hosted model for coding.
Hermes should be able to delegate engineering tasks to the same local model.
ResonantOS should be able to ask an Engineer agent to work in the background.
The model should be useful for agentic work, not just chat.
The system should run locally, without depending on cloud inference for every coding task.
The model we settled on for this phase was:
Qwen 3.6 35B A3B Q4_K_M, running on the GX10 through llama.cpp.
The GX10 acts as the inference server. The Mac Mini remains the orchestrator and software host.
Why Qwen 3.6 35B A3B?
We tested different options, including Gemma 4 26B and Qwen variants. The tradeoff was not only raw tokens per second. For agentic coding, we cared about:
instruction following
tool use
long context
stability
ability to handle parallel work
quality of code review
ability to run continuously
Qwen 3.6 35B A3B became the practical choice because it offered a better balance for coding and agentic use than the alternatives we tested locally.
The target setup became:
2 parallel active agents
around 200k context per active agent
always-on model availability
OpenCode and Hermes both pointing to the same local endpoint
The important lesson was that model selection is only part of the problem. The bigger question is: how do we make the system reliable when the model is not as strong as Codex or a frontier cloud model?
The First Problem: Prompting Is Not Enforcement
Initially, we configured OpenCode with a default engineering loop:
Implement pass
Review pass
Fix pass
Verification pass
The idea was that Qwen should not treat its first implementation as final. It should review itself, fix concrete issues, and then run deterministic checks.
This improved behavior, but it did not solve the problem.
In one test, OpenCode successfully wrote working code and passed tests. But when we inspected the result, it had still violated the task boundary. The prompt said to modify only two files, but OpenCode also edited package.json.
That is the key failure mode:
The model can understand the rule, repeat the rule, and still violate the rule.
This is not unique to Qwen. Smaller or local models are especially vulnerable to this kind of drift, but even stronger models benefit from external enforcement.
The conclusion was clear:
Prompting alone is not enough.
What Codex Helped Us Discover
Codex acted as the supervising engineer during these experiments.
Its role was not just to write code. It helped us:
inspect the actual files OpenCode changed
compare the result against the user’s original constraints
run independent verification commands
check Qwen and llama.cpp metrics
identify when OpenCode’s final report was incomplete
distinguish “tests passed” from “task correctly completed”
This mattered because OpenCode/Qwen often produced plausible summaries. But plausible summaries are not evidence.
Codex repeatedly checked the actual state:
git diff --name-only
npm run test:health
npm test
node scripts/health-check.mjs --jsonThat changed the process from “trust the agent” to “verify the artifact.”
The Workaround: Build a Runner Around the Model
The solution is to stop treating OpenCode/Qwen as the authority.
Instead, we treat it as a worker inside a deterministic engineering system.
The proposed architecture is an Engineer Runner.
The Runner owns:
task boundaries
allowed files
required commands
review passes
verification
final status
OpenCode/Qwen owns:
implementation
local reasoning
code edits
proposed fixes
The Runner does not trust the model’s claims. It checks the repository directly.
Human Workflow
There should be two ways to use the system.
1. Direct OpenCode Workbench
The user opens OpenCode and works interactively, similar to working with Codex.
But instead of launching an unrestricted task, OpenCode is started through a guarded runner:
engineer-runner openThe user provides:
repo
goal
allowed files or directories
required tests
strictness level
OpenCode still feels interactive, but the Runner enforces the rules.
2. ResonantOS Delegation
The user talks to Augmentor inside ResonantOS:
“Ask the Engineer to add JSON export to the health check.”
Augmentor creates a structured task contract and sends it to the Runner.
The user can continue working with Augmentor while the Engineer works in the background.
The result is not “OpenCode says it is done.”
The result is:
{
"status": "verified",
"changedFiles": [
"scripts/health-check.mjs",
"scripts/health-check.test.mjs"
],
"scopeOk": true,
"commands": [
{
"cmd": "npm run test:health",
"status": 0
}
],
"reviewFindings": []
}Architecture Diagram
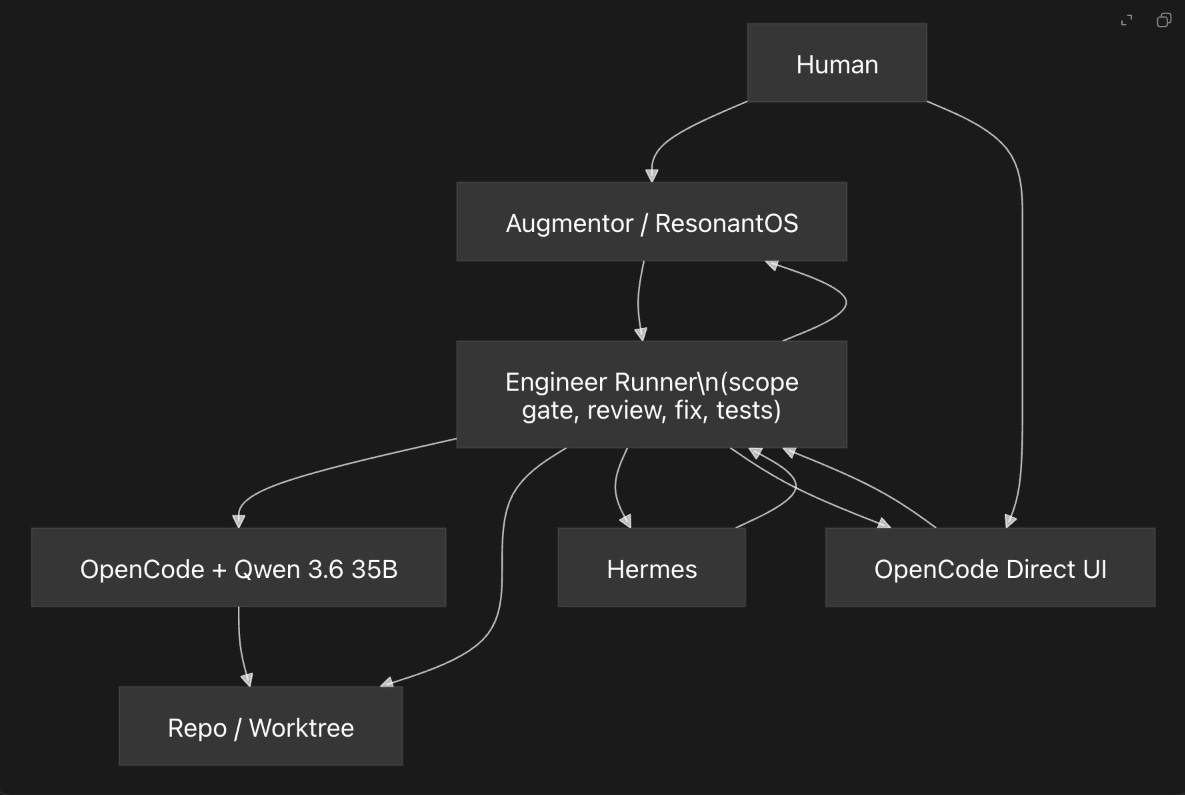
Why the Runner Matters
The Runner gives us guarantees the model cannot provide by itself.
For example:
Scope Gate
If the task allows only:
scripts/health-check.mjs
scripts/health-check.test.mjsThe Runner checks:
git diff --name-onlyIf package.json changed, the run fails automatically.
No model judgment required.
Verification Gate
If the task requires:
npm run test:healthThe Runner executes it directly.
The model does not get to claim success without evidence.
Review Separation
Instead of asking the same model to “please review yourself” in one response, the Runner can launch a separate review pass:
implement session
review session
fix session
verification session
This creates a more reliable loop, even if the same local model is used.
GX10 Architecture Challenges
The GX10 is powerful, but it introduces its own constraints.
The hardware uses NVIDIA’s newer GB10 / Blackwell-class architecture. That means many normal PyPI GPU wheels are not the best path. GPU workloads need to be handled carefully, usually through compatible NVIDIA containers or known-good builds.
We tested both llama.cpp and vLLM-style approaches.
vLLM with NVFP4 and DFlash is attractive because it may offer higher throughput and better serving behavior for specific models. But for an always-on local coding agent, stability matters more than peak throughput.
At this stage, the practical system uses llama.cpp because:
it is stable enough for continuous serving
it handles long context well in our tests
OpenCode and Hermes can call it through an OpenAI-compatible endpoint
it avoids the instability we saw while exploring vLLM setups
it keeps the architecture simpler for 24/7 use
The key insight is that the serving backend is only one layer. Even if vLLM improves speed later, the Runner pattern remains necessary.
What We Learned
The most important lessons were:
Local models can be useful coding workers.
Qwen 3.6 35B can write code, run tools, and fix issues.Local models should not be trusted as final reviewers.
They can pass tests while violating task boundaries.Prompting improves behavior but does not enforce behavior.
A model can understand the rule and still break it.Reliability comes from external structure.
Git diff, tests, allowed-file gates, and machine-readable reports are stronger than model self-reporting.Codex is useful as the supervising engineer.
It helped us identify failure modes, inspect real artifacts, and design a more robust workflow.The future system should not be “Qwen replaces Codex.”
The better architecture is: Qwen handles local labor, while the system enforces correctness.
The Direction
The next step is to implement the Engineer Runner as a first-class part of ResonantOS.
That gives us:
direct guarded OpenCode sessions
background Engineer delegation from Augmentor
Hermes-compatible task submission
deterministic reports
local 24/7 engineering capability
The final architecture is not “trust the local model.”
It is:
Use the local model as a worker inside a reliable engineering process.
That is the practical path toward a local AI engineering system that is slower than frontier cloud tools, but available, private, persistent, and increasingly dependable.
Transparency note: This article was written and reasoned by Manolo Remiddi. The Resonant Augmentor (AI) assisted with research, editing and clarity. The image was also AI-generated.